
Building Webhooks That Scale
Dan Farrelly · 7/27/2022 · 8 min read
Webhooks are core to integrating with other software services. Your application can react to external changes rather than having to periodically fetch - it’s a huge productivity and user experience gain.
While it’s easy to get started with webhooks - it’s just HTTP - it’s not as straightforward scaling webhooks beyond low volume usage. From experience scaling webhooks to millions of daily requests at Buffer, I’ve collected what you need to know to scale webhooks beyond initial implementation.
Importance of webhooks to Buffer.com
While I was CTO at Buffer for several years, we heavily depended on and leveraged webhooks at significant scale. Every day, the product processed millions of events through a few different webhook sources: Twitter’s Account Activity API, Facebook’s Messenger subscriptions, Instagram’s comments & stories webhooks, and Stripe’s webhook. The volume was rarely even and predictable - when one of our customers had a product outage or a huge giveaway, inbound events for comments, DMs, at-replies would spike to 10-100x typical volume.
We leveraged the webhook data to enable real-time customer support and engagement tools, ingest lots of engagement metrics for aggregated insights, and run data through ML models to provide features like sentiment analysis and intelligent tagging for comments and messages.
So how did we scale and ensure high reliability? Let’s start with the basics first.
What must a webhook do well?
If you’re already familiar with what a webhook is, you need to be aware of what they need to do well. It’s not too different from any core application performance requirements:
- High throughput - A webhook needs to be able to handle lots of messages quickly. It must be able to handle spikes in volume (10x+) gracefully.
- Low latency - A webhook should respond very quickly to prevent issues with timeouts for the request sender.
- Fault tolerance - Downtime will happen. A webhook should be able to recover and handle retried messages correctly.
v0.1 - Handling webhooks on your existing backend
Your version zero of your webhook likely starts with just adding a new endpoint onto your existing backend or API server to handle your new webhook. This approach works for an MVP, but it’s only viable at low throughput to start.

To increase reliability and throughput, you’ll need to scale your backend horizontally, running multiple instances of it. This may not be necessary if you’re already running a serverless backend.
Scaling your server horizontally can help with throughput, but at some scale, the webhook will experience back pressure with any downstream resources like your production database or an external API that you need to call. Having a bottleneck a layer deeper in your stack will create back pressure further up your stack, in your webhook http handler.
Handling volume spikes in your webhook have the potential to take down your entire backend if you’re not scaled appropriately. Webhook spikes should not take down your API for your user facing application. Conversely, issues with your API, like a fatal error or a botched deployment, could take down your webhook.
How to improve reliability?
An easy first step to improve the reliability is to decouple your webhook handler from your backend server or API. You then can horizontally scale your webhook service independently from your backend to ensure it’s highly available. Alternatively, you can move your webhook handler to a serverless function which can scale with load.

Decoupling and scaling horizontally are the first steps to improving reliability of your webhook handler for incoming requests, but there’s more you need to do for a production-scale implementation.
How to decrease response time?
Often with webhooks, you need to process the data somehow. It could be inserting multiple records into a database, triggering notifications, calling a third party API, or processing the data. If this processing takes too long, you run the risk of exceeding the timeout of the incoming requests. Webhook timeouts will be considered failures, which often means the request will be retried later. This can lead to duplicated side effects which, of course, is not ideal.

For these endpoints processing data, you should aim to respond immediately and do the processing in the background. Additionally, logging the request payload can ensure that you have a record of a given payload in the case there is any failure during background processing (if you have sensitive payload data, you’ll need to consider if or how you do this properly).
How to handle back pressure?
Back pressure in your system can cause issues at the point of processing. If you’re processing the data immediately, you don’t have any way to spread out (or slow down) the processing of the data - for example, it could hammer your database resulting in other issues. Alternatively, If processing is still happening within your webhook endpoint handler, slow processing can create back pressure on the http server itself, potentially resulting in missed requests.
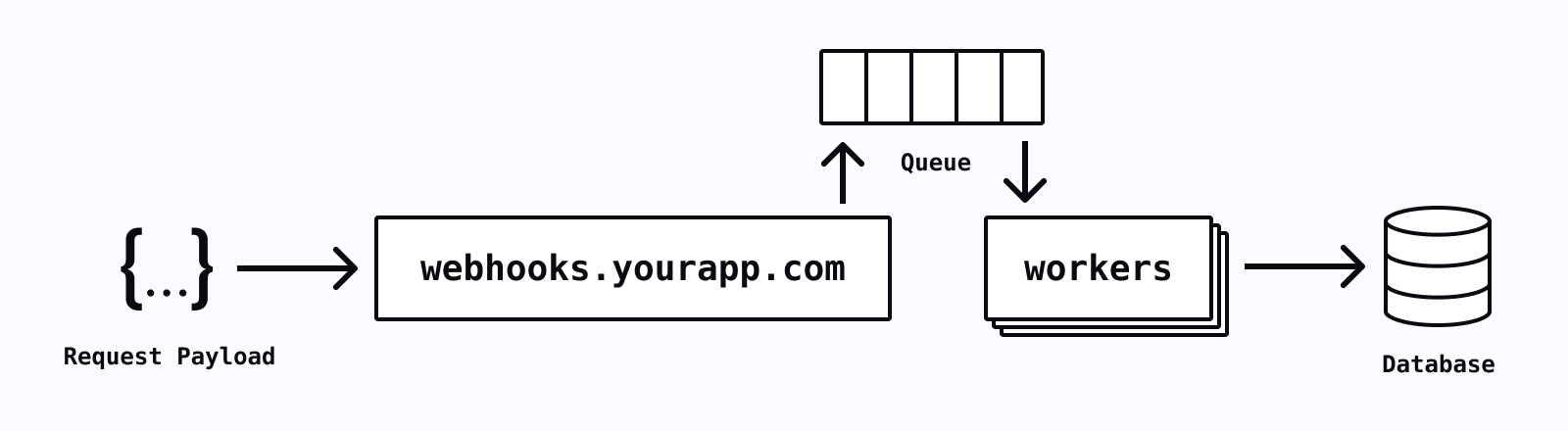
To control and handle back pressure, you can move the processing work to happen asynchronously, in a background job or worker. Your webhook receives the payload, immediately pushes the payload to a message queue, a log or a database for later processing. Your webhook also gains the benefit of quick response times since you’re not processing anything synchronously.
With the data flowing through a queue, you can now decide how you want to scale your workers, determining the level of concurrency and throttling exactly as you want. This will allow you to control the load the processing is placing on your database. You will be able to have more fine-grained control on scaling this, decoupled from the spikes in volume that your handle receives.
How to handle failures and payload changes?
Your code will have errors. Sorry. If your code fails to process something, maybe even due to a webhook payload change, you need to be able to recover. In queuing systems, depending on your configuration a worker may try to retry processing a given message n number of times before the message might expire.
You’ll have to set up a dead letter queue or some sort of archive that will allow you to inspect these failed messages, fix your code, and handle the messages properly. You’ll need to configure this processing of retries or replays event payloads that you missed, otherwise there will be missing data (state) for your users.
How to handle downtime or webhook outages?
Outages happen. It may be your cloud provider’s fault, it may be yours. The service sending you webhook requests may also encounter issues and stop sending event payloads for period of time. You will need to make sure that your worker code is idempotent, meaning that if the handler runs multiple times it produces the same side effects and results exactly once.
It’s important to assume that you may receive any webhook more than once. A starting point for idempotency is to ensure that each unique webhook payload is handled once — whether by storing IDs, checksums, or building out exactly once semantics. Your code will be better off for it and you’ll be able to recover from outages gracefully and avoid data issues.
Putting it all together
You can build all of this out yourself as many software teams have done in the past. You can also choose to incrementally apply some of these tips as your system needs to scale and become more reliable for your customers. You may have even built out all of these parts again and again at your current job and your last job. Unfortunately, your customers don’t care how awesome your webhook handling setup is or how sweet your terraform is for configuring it all.
We’ve built all of this into Inngest to give you everything you need out of the box. It’s easy to set up webhook handlers with inline payload transformations, a queue to handle incredible load, serverless functions that replace the need to run your own workers, automatic retries, throttling controls, full event payload archive and logs, and a CLI to easily test your code that handles the messages, including replaying production data locally. If any of this interests you, check our docs or give Inngest a spin.
Takeaways
If you are running a reliable webhook at any decent scale or throughput, you need to decouple, add a queue, and have rock solid, idempotent retries. I hope that this has given you a blueprint on how you can scale your own webhooks as your user base grows.
If you don’t want to roll it yourself - check out Inngest. Come chat with us on Discord, we’d be happy to share free advice for scaling your webhooks with Inngest or building our your own setup.
Help shape the future of Inngest
Ask questions, give feedback, and share feature requests
Join our Discord!